Overview and motivation
A single text document often has multiple semantic aspects. A single news article related to politics may have aspects related to trade, technology and defense. Therefore, often a document needs to be tagged to multiple labels/categories, instead of a single category. Most of the classification algorithms deal with datasets which have a set of input features and only one output class. However, in reality the problem might be different from a typical binary or multiclass classification, as often a document or an image can be associated with multiple categories rather than a single category.
An introduction of enormous amount of documents belonging to multiple categories in the legal domain, makes it an attractive area for employing automated solutions. In this project we explore a public multi labelled legal text dataset that has been manually annotated over a decade. It contains laws related to the European Union, including treaties, legislation, case-law and legislative proposals, in 24 different languages. This is popularly known as the EUR-Lex dataset containing about twenty five thousand documents, around seven thousand labels and in several European languages. A skewed distribution of multiple labels per document, along with existence of the same data in multiple languages, makes this dataset an interesting proposition. Few publications have used an older version of the dataset which had around four thousand labels. The ones that have used this have reported relatively poor F1 values in the range of 40% (referred to as EUROVOC)[1] (which may be fair, given the high number of labels). There is no publications for the new dataset (having around 7000 labels), which motivates us to explore the problem of multilabel classification on this dataset.
Multilable v/s Multiclass classification
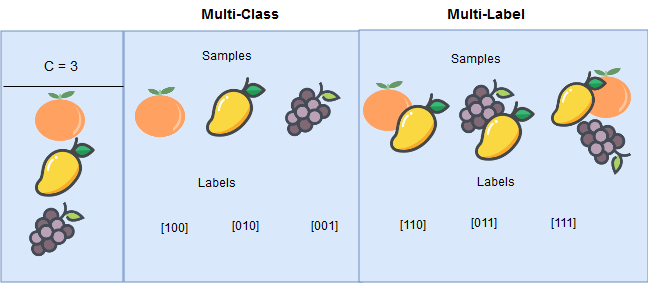
In multi-label classification, each instance in the training set is associated with a set of labels, instead of a single label, and the task is to predict the label-sets of unseen instances, instead of a single label.
There is a difference between multi-class classification and multi-label classification. In multi-class problem the classes or labels are mutually-exclusive, i.e. it makes the assumption that each instance can be assigned to only one label. E.g - an animal can be either a dog or a cat but not both. But in multi-label problem multiple labels may be assigned to an instance. E.g - a movie can belong to a comedy genre as well a detective genre.
Project objectives
Can we use machine learning techniques to automatically annotate legal documents?
To answer the question we need to answer some research questions:
- How well the classifiers perform over Eur-Lex dataset for two languages (English and Deutsch).
- How the classifiers’ performance changes with different features- one with term frequency-inverse document frequency(tf-idf), another with term incidence.
- Which flavour of multilabel transform algorithm perform best among all, the one which considers label correlation or the one which does not.
- How the classifiers’ performance changes when the number of labels is reduced (disabling the imbalanced labelsets).
Design overview (algorithms and methods)
- Pre-processing:
- Statistical exploration:
- Basic exploration - distribution of attributes/labels
- Multi-label specific exploration- labelset distribution, relationship among labels, and relationship between attributes and labels/labelsets
- Classification:
- Apply the classifiers (Nearest Neighbour, Random Forest, XGBoost) over the preprocessed dataset (tf-idf and term incidence) for German and English text, and for three flavours of multilabel classification methods:
- Apply the classifiers (Nearest Neighbour, Random Forest, XGBoost) over the preprocessed dataset (tf-idf and term incidence) for German and English text for reduced labels, and for two flavours of multilabel classification methods:
- Binary Relevance (BR)
- Label Powerset (LP)
- The following evaluation measures has been used primarily to assess the multilabel predictive performance:
- Accuracy
- Hamming Loss
- Micro F1
- Macro F1
- Compare the performance of the state-of-the-art classifiers for:
- Two languages (English and German)
- Two kinds of features (tf-idf and incidence)
- Three flavours of multilable classification algorithms (Binary Relevance, Label Powerset, Classifier Chain)
- Reduced labels
Dataset
We have considered - European Union law documents (EUR-Lex).
The data in different European languages is located inside the software distributed by European Union. We have considered two languages- English and German. They can also be downloaded directly from the links below:
- English
- German
GitHub URL
The R scripts, process notebook and other resources have been stored at the repository-
https://github.com/suhitaghosh10/EurLexClassification.git
Screencast

R packages
The following packages must be installed in R-Studio.
## The script installs the necessary packages if not already installed, and then loads them
packages <- c(
"textstem",
"stringi",
"dplyr",
"data.table",
"tm",
"textclean",
"XML",
"RWeka",
"tidyr",
"tidytext",
"parallel",
"mldr",
"utiml",
"tidytext",
"ggplot2",
"RColorBrewer",
"udpipe",
"kknn",
"xgboost",
"randomForest",
"matrixStats",
"rmarkdown",
"wordcloud",
"ggraph",
"igraph",
"tidyverse",
"gridExtra",
"kableExtra",
"knitr"
)
verify.packages <- function(pkg) {
new.pkg <- pkg[!(pkg %in% installed.packages()[, "Package"])]
if (length(new.pkg))
install.packages(new.pkg, dependencies = TRUE)
sapply(pkg, library, character.only = TRUE)
}
verify.packages(packages)References
1. Loza Mencía E, Fürnkranz J. Efficient multilabel classification algorithms for large-scale problems in the legal domain. In: Francesconi E, Montemagni S, Peters W, Tiscornia D, editors. Semantic processing of legal texts: Where the language of law meets the law of language. Berlin, Heidelberg: Springer Berlin Heidelberg; 2010. pp. 192–215. doi:10.1007/978-3-642-12837-0_11.
2. Gibaja E, Ventura S. A tutorial on multilabel learning. ACM Comput Surv. 2015;47:52:1–52:38. doi:10.1145/2716262.
3. Charte F, Charte D. Working with multilabel datasets in r: The mldr package. R Journal. 2015;7.
4. Rivolli A. Utiml: Utilities for multi-label learning, 2016, r package version 0.1. 0. Available: CRAN R-project org/package= utiml.
5. Godbole S, Sarawagi S. Discriminative methods for multi-labeled classification. In: Pacific-asia conference on knowledge discovery and data mining. Springer; 2004. pp. 22–30.
6. Boutell MR, Luo J, Shen X, Brown CM. Learning multi-label scene classification. Pattern recognition. 2004;37:1757–71.
7. Read J, Pfahringer B, Holmes G, Frank E. Classifier chains for multi-label classification. Machine learning. 2011;85:333.